
Context in SQL AI Agents: The Three Layers Behind Reliable Answers
Part 2 of the Foundations of SQL AI Agents series

The four-component architecture from the previous post gives a SQL AI agent its shape. The prompt handler assembles, the API handler talks to the model, the query parser cleans up, and the database handler runs the SQL. Yet shape alone does not decide whether the agent gives the right answer. What decides that is the information arriving at the model — what it knows about the schema, the SQL dialect, and the business domain when it sits down to write a query.
See also part 1 in this series:
Introduction to SQL AI Agents: The Four Components Behind Natural Language SQL

Most organizations store their most valuable information inside relational databases. Yet many of the people who need answers from that data don’t write SQL. Business stakeholders want to understand trends, support teams need operational insights, and product managers want to explore customer behavior, but translating those questions into database queri…

Data engineers building these systems, AI practitioners deploying them, and product teams shipping them in customer-facing tools quickly converge on the same observation: failures rarely come from the model itself. They come from missing context.
Context is what bridges that gap.
LLMs are probabilistic systems. When information is missing, they fill the gaps with whatever is most likely. Sometimes that lands close enough to be useful. Often it does not. A model that has never seen your schema will invent table names that sound plausible. A model that has never seen your business definitions will guess at what “active customer” or “fiscal quarter” means. A model that has never been told which database engine you’re using will produce SQL in a dialect that looks correct and silently breaks at execution.

The interesting consequence is that the quality of context often matters more than the size of the model. A mid-tier model with rich, well-assembled context will frequently outperform a frontier model running on a vague prompt. Cost-efficient SQL AI agents are usually well-contexted.
This is the second installment in the Foundations of SQL AI Agents series, and it is intentionally conceptual — focused on the mental model rather than the implementation. Many of these ideas are covered in depth in my LinkedIn Learning course, Build with AI: SQL Agents with Large Language Models, where we build a working SQL AI agent from the ground up. The next post in this series will move from concepts to code, walking through a complete agent build.
What Is Context in a SQL AI Agent?
Context is everything the model receives beyond the user’s question.
A useful way to think about it: if the LLM is the engine, the prompt is the brain. The engine does the reasoning; the brain tells it what the reasoning is about. A SQL AI agent succeeds when its prompt — and the context within it — provides the model with enough information to answer deterministically rather than probabilistically.
Consider a question that looks simple in isolation:
Which states had the highest total sales last quarter?
For a model with no context, this is several open questions at once. Which table holds the sales? What column stores the state? Are state values stored as full names, like California, or abbreviations, like CA? Is last quarter the previous calendar quarter or the previous fiscal quarter, and when does the fiscal year start? Which SQL dialect should the result use?
A model without context will guess at all of those. A model with context does not need to guess. The same question, with the right scaffolding, becomes mechanical.
That difference, between guessing and knowing, is what context produces. And the context a SQL AI agent uses comes from three different places.
The Three Layers of Context
Context is not one thing. It is a stack of three layers, each answering a different kind of question for the model. The first layer is automatic. The second comes from the team building the agent. The third is the agent’s own setting.
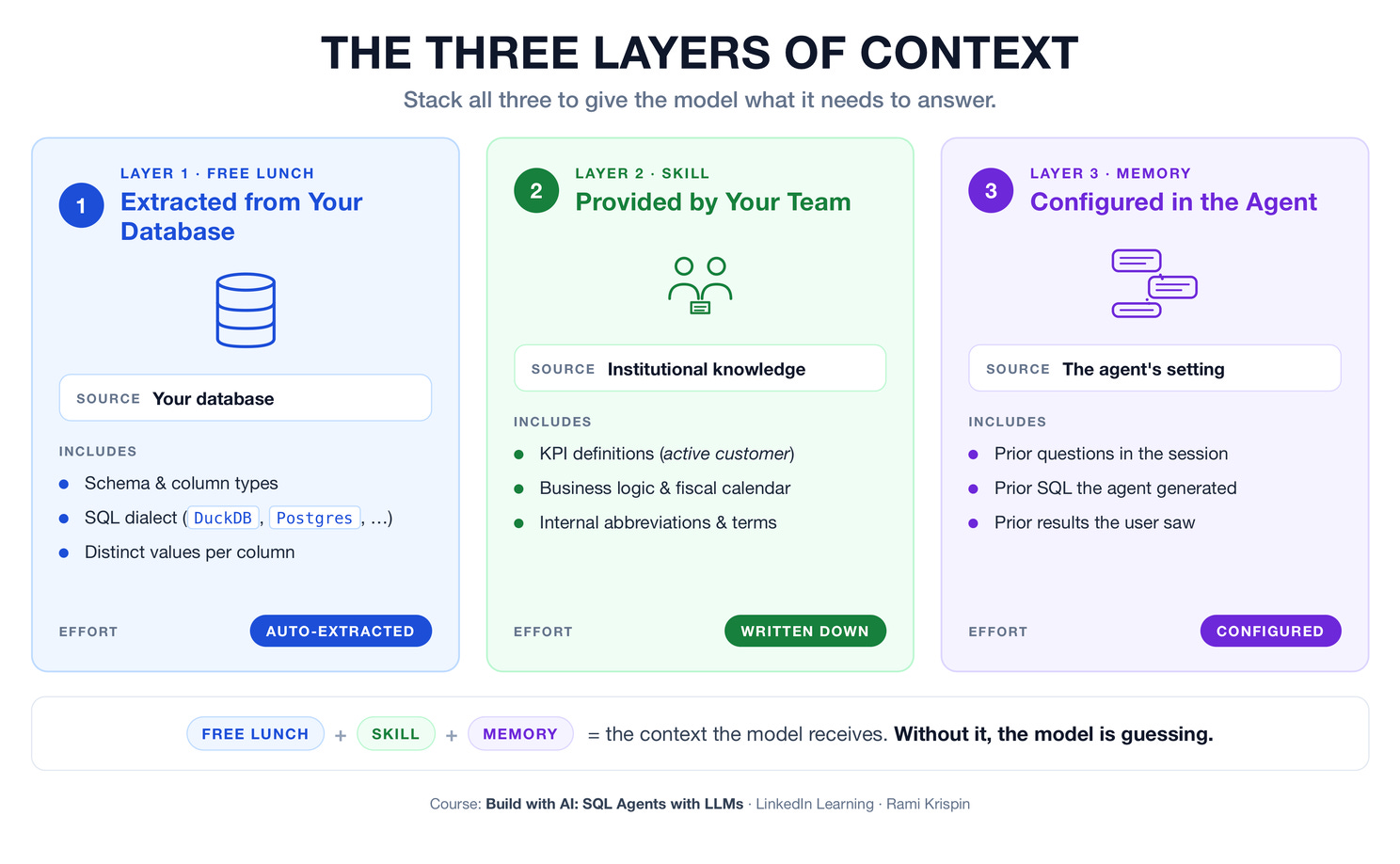
Together, these three layers are what turn a generic LLM into an SQL AI agent that knows your data.
1. The Free Lunch — Context Extracted from Your Database
The first layer is the context already sitting inside your database.
Schema, column types, the engine’s SQL dialect, and the distinct values in categorical columns are all available without anyone having to write them down by hand. Schemas and types tell the model what the data looks like. Running DESCRIBE retail_sales returns the column names and the type of each one — exactly the information the model needs to write a syntactically correct query. The database engine itself, whether DuckDB, PostgreSQL, BigQuery, or Snowflake, defines the dialect; naming it in the prompt removes a class of subtle errors that look correct on the page and fail at execution.
Distinct values matter for any column that the model will compare. A query that filters by state needs to know whether the values are stored as California or CA. A short SELECT DISTINCT against the relevant column surfaces exactly that, and the model stops guessing.
This is the layer that earns the name free lunch. Each piece can be extracted in a few lines of code, and the user never has to provide it. When the agent does that work automatically, the only thing the user contributes is the question.
2. The Skill Layer — Context Only You Can Provide
The second layer is the context that the model cannot derive from the data itself, or unique internal business logic that the model was not exposed to during training.
It is the institutional knowledge that lives in people’s heads, in internal documents, and in the conventions of how a particular organization talks about its own metrics. This includes definitions of what counts as an active customer, what churn means in this business, and when the fiscal year starts. It includes domain terminology: internal abbreviations, product code names, and the company’s definitions of different tiers. It includes business logic: which categories roll up into which segments, which records are excluded from headline metrics, and how returns affect revenue.
None of that information lives in the schema. It lives in the team. The agent has to be told.
The implementation is straightforward. These definitions become part of the prompt scaffolding the agent assembles for every question. The hard part is not the engineering. The hard part is doing the work of documenting the institutional knowledge. This is where building a useful SQL AI agent becomes as much a knowledge-management problem as a software problem.
3. The Memory Layer — Context That Persists Across Turns
The third layer is the context that builds across a conversation rather than a single question.
Real users do not ask one question and stop. They ask a question, see the answer, and follow up:
Show me total sales by state.
Now break it down by quarter.
The second question only makes sense in light of the first. Without memory of the prior turn, the agent treats every question as if it had never seen the user before.
Memory is a property of the agent itself, not of the database or the team. It is a configuration: the application stores recent turns, replays the relevant ones into the next prompt, and lets the model treat the conversation as continuous rather than disconnected. Different applications need different amounts of memory. A one-shot reporting tool may need none. An interactive analytics assistant needs enough to feel coherent.
When memory works, the agent feels like it is following the conversation. When it does not, every question starts from zero.
Closing Thoughts
Each of the three layers answers a different question for the model. The free lunch tells the model what the data looks like. The skill layer tells the model what the data means. The memory layer tells the model what the conversation has covered so far. Stacked together, they replace what the model would otherwise have to guess.
That stack is what makes the difference between an impressive demonstration and a SQL AI agent that holds up against real questions on real data.
The model still matters. A capable model on a well-contexted prompt is more reliable than a less capable one. But the model tier sits on top of context, not in place of it. A frontier model running on a vague prompt will produce confident-sounding SQL against a table that does not exist. A mid-tier model with the right schema, the right business definitions, and a clear sense of what was asked five turns ago will quietly produce the right answer.
In the next article, we’ll move from concepts to code — building a SQL AI agent from scratch and watching each component, and each layer of context, land in real Python.
Interested in learning more about SQL AI agents?
If you’d like to dive deeper into SQL AI agents, I’ve put together two LinkedIn Learning courses that cover the topic from beginner to advanced levels.
Build with AI: SQL Agents with Large Language Models – an introductory course that walks through the fundamentals of SQL AI agents and shows how to build one from scratch.
Build with AI: SQL AI Agents in Production – a more advanced course focused on the challenges of deploying SQL AI agents in real-world environments, including the considerations that come with taking them to production.
Whether you’re just getting started or thinking about production use cases, I hope you’ll find them helpful.