


The PandasAI Project, Learning SQL Book, Fine-Tuning Local LLMs
A weekly curated update on data science and engineering topics and resources.

This week's agenda:
Open Source of the Week - The PandasAI project
New learning resources - Getting started with Docker Model Runner, MCP Dev days, context engineering, training Qwen 3 model, fine-tuning local LLMs
Book of the week - Learning SQL by Alan Beaulieu
I share daily updates on Substack, Facebook, Telegram, WhatsApp, and Viber.

Are you interested in learning how to set up automation using GitHub Actions? If so, please check out my course on LinkedIn Learning:
Open Source of the Week
This week's focus is on the PandasAI project. This project, as the name implies, is a combination of the Pandas library with LLMs. Hence, it enables users to interact with Pandas DataFrame using natural language.
Project repo: https://github.com/sinaptik-ai/pandas-ai
Key Highlights and Functionality
Data preparation layer that enables the user to define semantic data schemas and establish data relationships across different tables
Supports various data formats such as Parquet, CSV, etc.
Translate natural language to executable code
Generate dynamic visualization and charts
Provides automated data insights
Here is a simple workflow with the library (via the project documentation):
import pandasai as pai
from pandasai_openai.openai import OpenAI
llm = OpenAI("OPEN_AI_API_KEY")
pai.config.set({
"llm": llm
})
# Sample DataFrame
df = pai.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"revenue": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000]
})
df.chat('Which are the top 5 countries by sales?')This returns:
China, United States, Japan, Germany, AustraliaMore details are available in the project documentation.
License: MIT
New Learning Resources
Here are some new learning resources that I came across this week.
Getting Started with Docker Model Runner
This tutorial focuses on getting started with Docker Model Runner, and it is the first in a series that focuses on using Docker Model Runner to run LLMs locally. This tutorial is available for Medium members:
https://medium.com/data-science-collective/getting-started-with-docker-model-runner-c2ed4ce4b5ee
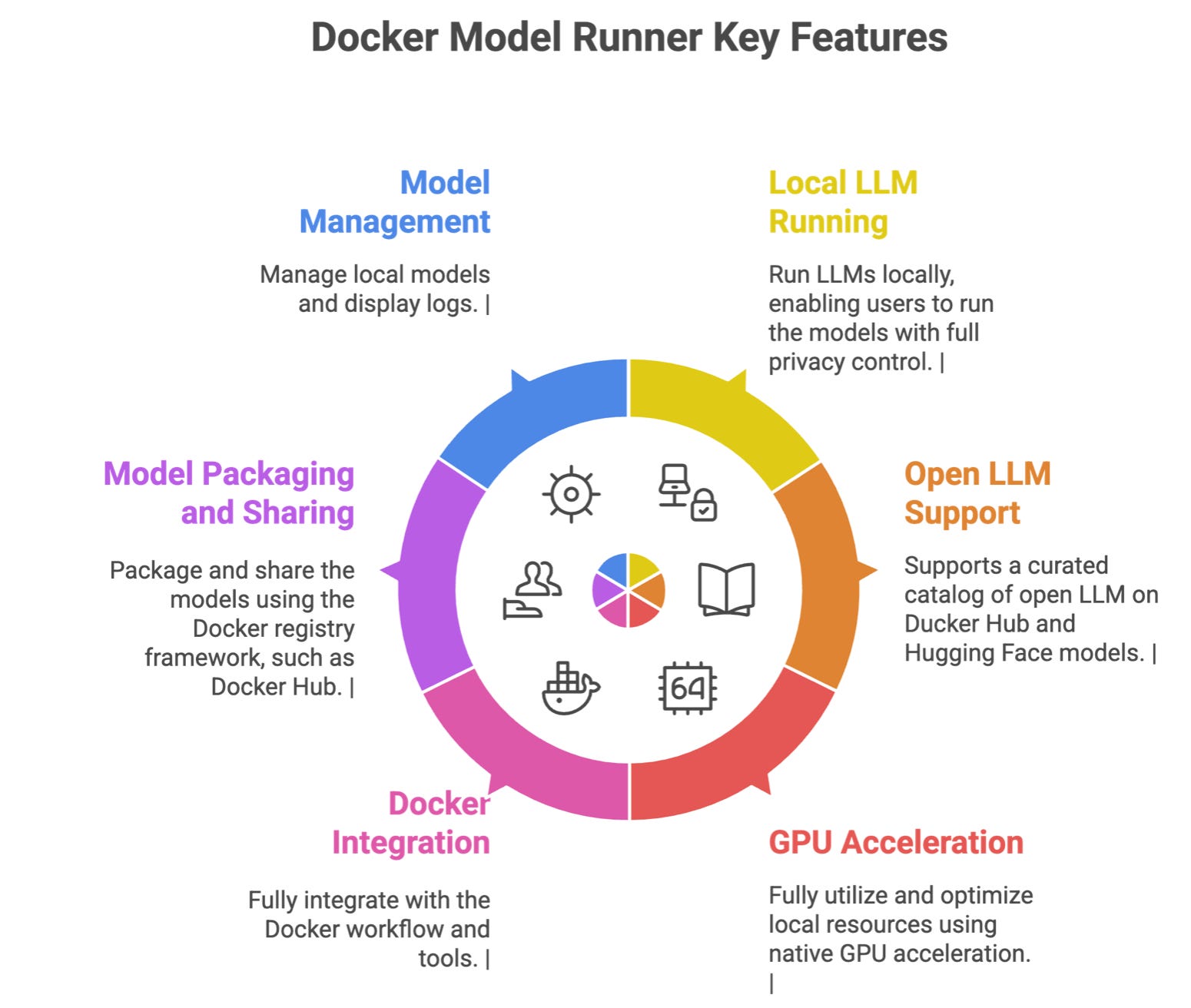
Alternatively, this tutorial and the rest of the sequence are available on The AIOps Newsletter:

MCP Dev Days
The talks from the Microsoft Developer MCP Dev Days conference are now available online. The conference focuses on different use cases of the Model Context Protocol (MCP) and its ecosystem. This includes topics such as:
MCP in production
MCP with AI agents
Security
Supporting tools
Context Engineering Explained
This short and concise tutorial by Shaw Talebi explains what context engineering is and some practical tips for setting up a prompt.
Code & Train Qwen 3
This new tutorial by freeCodeCamp focuses on training and tuning the Qwen 3 model.
Fine-Tuning Local LLMs
The following tutorial by NeuralNine provides a step-by-step guide for fine-tuning LLMs locally with Unsloth and Ollama.
Book of the Week
I share a book here every week, and as far as I remember, I don't think we have had an SQL book so far. This week's book is Learning SQL by Alan Beaulieu. The book focuses on the foundation of SQL, covering core concepts with practical examples. This includes topics such as:
SQL basic operations
Creating and populating a database
Query primer
Working with sets
Grouping an daggregates
Conditional logic
Indexes and constraints
Working with multiple tables

This book is ideal for data practitioners—from aspiring data scientists and analysts to ML/AI architects and database administrators—who want a solid, comprehensive foundation in SQL, bridging from core querying to advanced and big data use cases.
The book is available online for reading on the O'Reilly platform (for subscribers) and can also be purchased in a printed version on Amazon.
Have any questions? Please comment below!
See you next Saturday!
Thanks,
Rami
PandasAI is super cool library and make easy to adopt in data pipelines and EDA steps