
The exo Project, Getting Started with Hermes and Pi Agents, Building LLMs from Scratch | Issue 87
A weekly curated update on data science and engineering topics and resources.

This week's agenda:
Open Source of the Week - The exo project
New learning resources - Getting started with Hermes AI agent, building a Slack Python bot, introduction to Pi agent, Gemma 4 coder app
Book of the week - Building Large Language Models from Scratch: Design, Train, and Deploy LLMs with PyTorch by Dilyan Grigorov
The newsletter is also available on LinkedIn and Medium.

Are you interested in learning about SQL AI agents in production? If so, please check out my LinkedIn Learning course:
Open Source of the Week
I shared a few posts recently about why, in my biased opinion, Apple won the AI race between Anthropic, OpenAI, and Google. It is a combination of the token economy that went out of control and Apple’s technology that enables running local LLMs thanks to its Unified Memory architecture. This architecture enables the CPU, GPU, and Neural Engine to share a single pool of high-bandwidth, low-latency memory integrated directly onto the silicon chip. In addition, a small feature was introduced in macOS 26.2 (Tahoe) that enables clustering multiple Macs for AI and high-performance computing using RDMA (Remote Direct Memory Access) over Thunderbolt 5. This means you can now take four Mac Studies with 64 GB of RAM and cluster them into a 256 GB RAM unified memory pool available for LLMs.
This is where the exo project comes into the picture. This open-source project enables clustering multiple devices while leveraging their unified memory to run LLMs.
Project repo: https://github.com/exo-explore/exo
Key Features
Automatic Device Discovery: Devices running exo automatically discover each other - no manual configuration.
RDMA over Thunderbolt: exo ships with day-0 support for RDMA over Thunderbolt 5, enabling 99% reduction in latency between devices.
Topology-Aware Auto Parallel: exo figures out the best way to split your model across all available devices based on a real-time view of your device topology. It takes into account device resources and network latency/bandwidth between each link.
Tensor Parallelism: exo supports sharding models, for up to 1.8x speedup on 2 devices and 3.2x speedup on 4 devices.
MLX Support: exo uses MLX as an inference backend, and MLX is distributed for distributed communication.
Multiple API Compatibility: Compatible with OpenAI Chat Completions API, Claude Messages API, OpenAI Responses API, and Ollama API - use your existing tools and clients.
Custom Model Support: Load custom models from the Hugging Face hub to expand the range of available models.
Source: Project repo
The exo has a native dashboard that enables you to manage the cluster. The screenshot below from the project repo represents a cluster of four 512GB M3 Ultra Mac Studio running DeepSeek v3.1 (8-bit) and Kimi-K2-Thinking (4-bit):
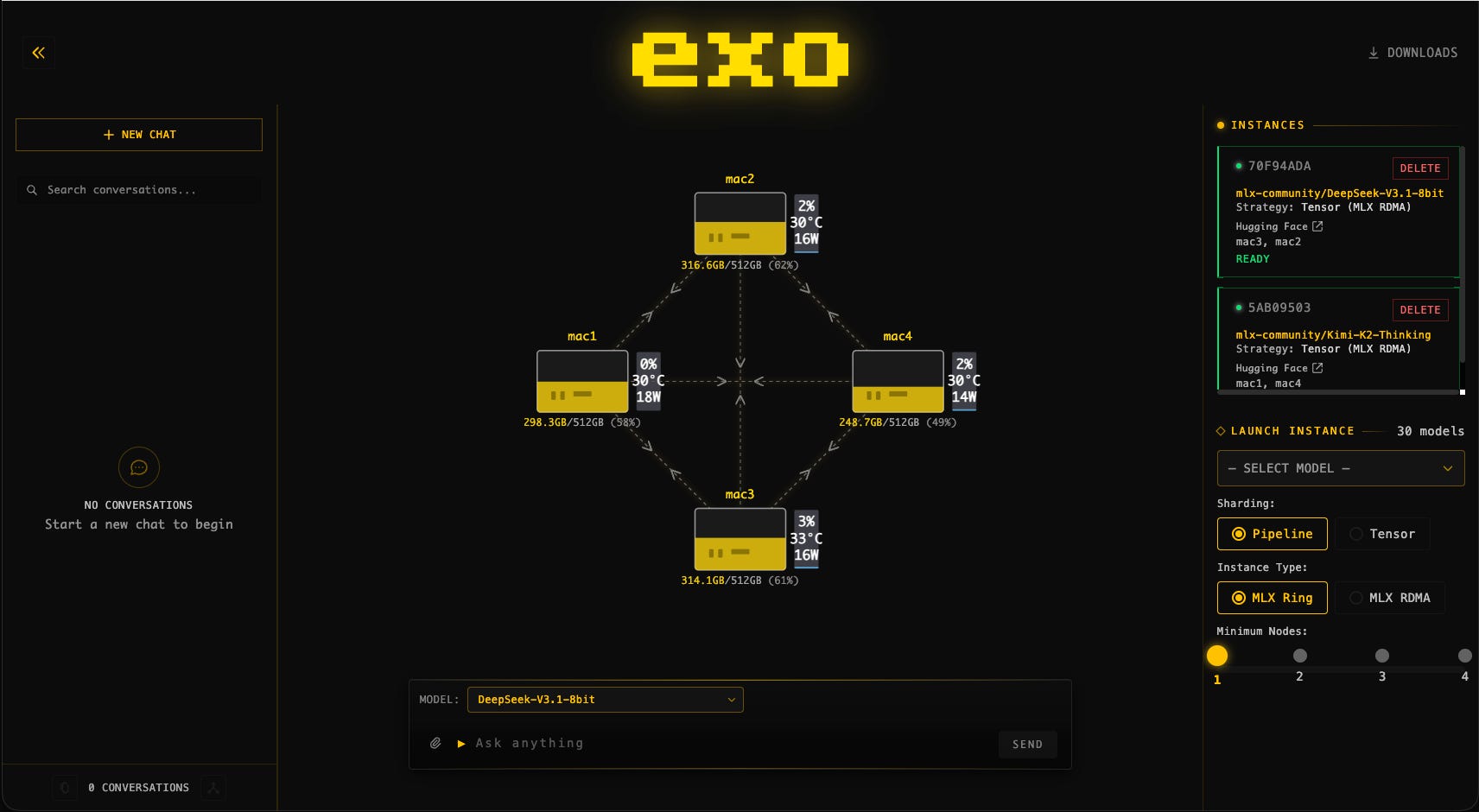
More details are available in the project API documentation.
License: Apache 2.0
New Learning Resources
Here are some new learning resources that I came across this week.
Getting Started with Hermes AI Agent
Hermes Agent is an open-source, autonomous AI agent framework developed by Nous Research that runs continuously to automate tasks and improve its own capabilities over time. The following resource from Onchain AI Garage provides an in-depth guide to getting started with Hermes, from setup to token optimization.
Build a Slack Bot with Python
The following tutorial by NeuralNine provides a guide for building and setting up a simple Slack bot with Python.
Getting Started with Pi AI Agent
This tutorial by Alejandro AO introduces the Pi agent. The tutorial covers the following topics:
Pi Agent installation and core philosophy
Model switching and provider configuration
Custom prompts, skills, and themes
Building extensions with TypeScript
Session management and export
Gemma 4 Coder Desktop App
The following video introduces a new open-source project that provides a code generator based on Gemma 4.
Book of the Week
Book of the Week
This week’s focus is on an LLM book - Building Large Language Models from Scratch: Design, Train, and Deploy LLMs with PyTorch by Dilyan Grigorov. The book, as the name implies, focuses on LLMs architecture and illustrates how to build one from scratch using Python, PyTorch, and CUDA. The book covers both theoretical concepts and practical applications.
Topics Covered
LLM foundations and setup — configuring development environments, working with tensors, embeddings, and gradient descent using PyTorch.
Tokenization and embeddings — preparing text data and converting language into model-ready representations.
Transformer internals — implementing attention mechanisms, RMSNorm, rotary positional embeddings (RoPE), SwiGLU activations, Grouped Query Attention (GQA), and Mixture of Experts (MoE).
Building GPT-style architectures — coding transformer layers and complete autoregressive language models from scratch.
LLM training workflows — pretraining, midtraining, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF).
CUDA optimization and GPU acceleration — integrating custom CUDA kernels and optimizing memory and performance for large-scale training.
Dataset engineering — filtering, deduplication, batching, and preparing large corpora for model training.
Inference and deployment — evaluating models, generating text, and deploying custom LLMs for practical applications.

This book is ideal for software developers, machine learning engineers, data scientists, and AI practitioners who already know Python and want a deep, implementation-level understanding of how modern LLMs are architected, trained, optimized, and deployed in practice.
The book is available for purchase on the publisher’s website and on Amazon.
Have any questions? Please comment below!
See you next Saturday!
Thanks,
Rami
Good reads this week . Thanks for sharing.
Exo is Interesting project to know about. Is it possible to cluster between MacBook and Mac mini or only it works for studios ?