
NumPyro Forecast, The Orange Book of Machine Learning | Issue 95
A weekly curated update on data science and engineering topics and resources.

This week’s agenda:
Open Source of the Week - NumPyro Forecast
New learning resources - How I Built My Coding Agent - Architecture Overview, Command Line Basics for Beginners, How Model Context Protocol (MCP) actually works, DuckCon #7 (Amsterdam, June 2026), Invoice Automation System in Python
Book of the week - The Orange Book of Machine Learning - Green edition by Carl McBride Ellis
The newsletter is also available on LinkedIn, Substack, and Medium.

Are you interested in learning about SQL AI agents in production? If so, please check out my LinkedIn Learning course:
Open Source of the Week
This week’s focus is on the NumPyro Forecast project.
NumPyro Forecast is an open-source project by Juan Orduz (juanitorduz) that ports Pyro’s forecasting module to JAX and NumPyro for Bayesian time-series forecasting. Rather than ship another “fit-any-series” AutoML tool, it keeps you in control of the generative model and handles the plumbing around it: you write the NumPyro model, and the package takes care of the train/forecast split, inference, and evaluation. A single model both trains and forecasts — the in-sample time latents and the forecast horizon use separate sample sites, so the variational guide is never resized, and the horizon itself is inferred from the array shapes. The goal is a clean, explicit path from a model definition to probabilistic forecasts and scores, without a hidden model zoo or automatic feature pipelines getting in the way.
Project repo: https://github.com/juanitorduz/numpyro_forecast
Key Features
One model for training and forecasting — the same generative model handles both, with in-sample latents and the forecast horizon kept on separate sites so the inference guide stays fixed in size.
Two inference backends — stochastic variational inference through the
Forecasterclass and Hamiltonian Monte Carlo / NUTS throughHMCForecaster.Functional core plus OOP shim — a pure functional API with an explicit
Horizonvalue and explicitPRNGKeythreading, alongside a thin class-based API; the two are interchangeable, so you can fit with one and forecast with the other.Pyro-compatible API — the class-based shim mirrors Pyro’s
pyro.contrib.forecastinterface, so existing Pyro forecasting code maps over with the sametime_series(...)andpredict(...)calls.Backtesting and metrics — rolling-window backtesting with both probabilistic and point metrics, including CRPS, to evaluate forecasts.
Univariate to hierarchical — works across univariate, multivariate, and hierarchical models.
Pyro array layout - follows Pyro’s convention of time on the axis
-2, the observation dimension at-1, and batch dimensions to the left.You own the model — by design, it is not an AutoML library; there is no pre-built model zoo or feature engineering, so the modeling choices stay explicit and yours.
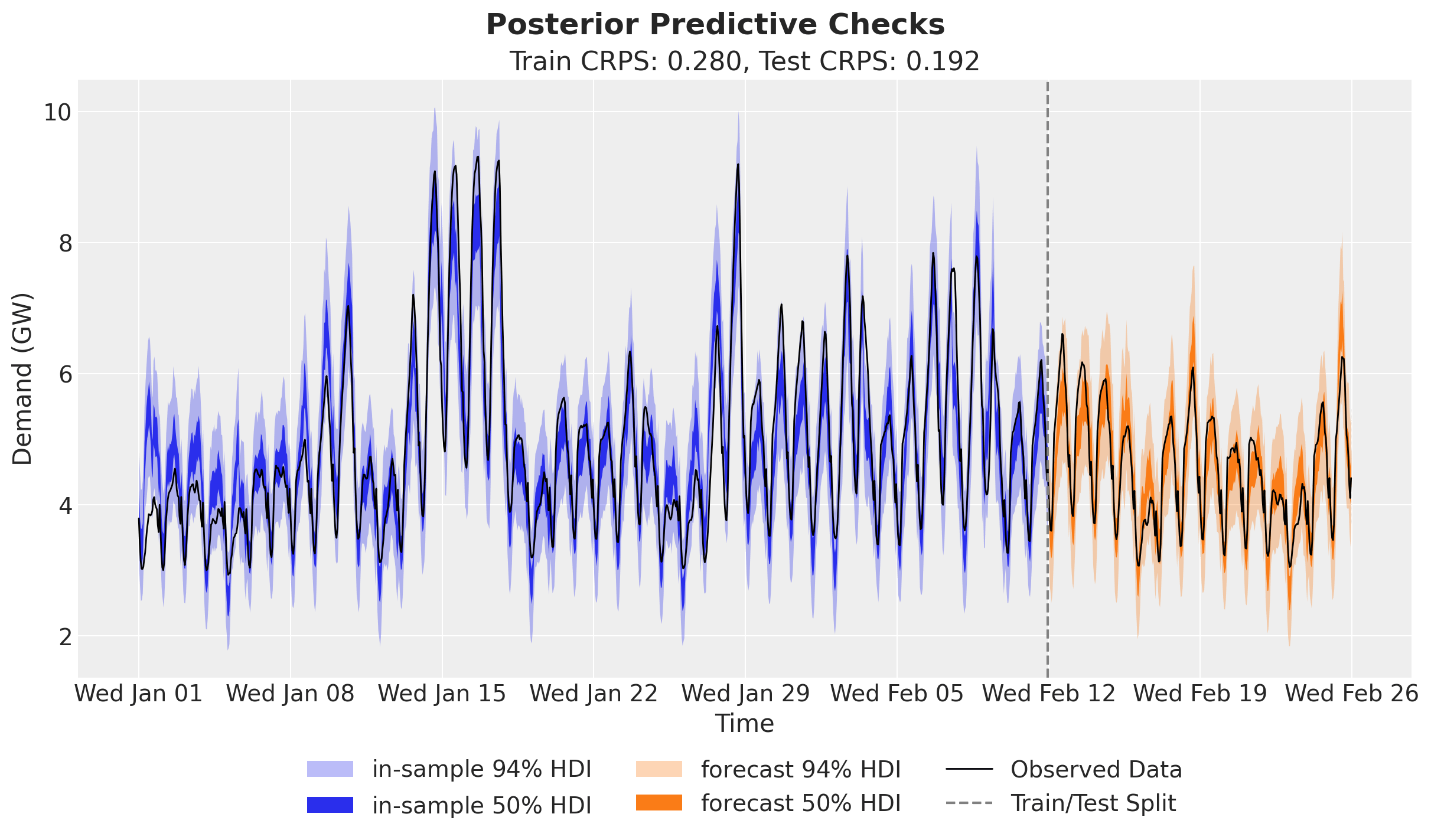
The package requires Python 3.12+ and is available on PyPI (pip install numpyro_forecast). More details are available in the project documentation.
License: Apache-2.0
New Learning Resources
How I Built My Coding Agent - Architecture Overview
This walkthrough from Alejandro AO breaks down Tau, a minimalist coding-agent harness he built in Python — inspired by Pi and written as a readable reference for how coding agents are actually assembled. It covers the three-layer design: a model-streaming layer (tau_ai), a portable agent harness holding the loop, tools, and sessions (tau_agent), and the coding CLI with local files, shell tools, skills, commands, and a terminal UI (tau_coding).
Claude API Crash Course
This short hands-on series from Net Ninja is a quick way to get started with the Claude API - five videos, around 40 minutes in total, that build a small app end to end rather than walking through the docs. It covers project setup and the first API call, sending a message to the model, making the prompt dynamic, structuring the output with Zod, and rendering the model’s response as HTML.
Portfolio Analysis in Python with QuantStats
This tutorial from NeuralNine walks through QuantStats, Ran Aroussi’s Python library for portfolio analytics. It covers the library’s three modules — performance and risk metrics like the Sharpe ratio, volatility, and drawdowns (stats), visualizations for returns and rolling statistics (plots), and HTML tear sheet reports (reports) — plus its built-in Monte Carlo simulations for probabilistic risk analysis.
Invoice Automation System in Python
This 36-minute tutorial from NeuralNine walks through an invoice automation project in Python, with a RavenDB-backed example for extracting structured fields from invoices and querying stored invoice data. The linked code includes a sample invoice PDF, Docker Compose for RavenDB, extraction prompt files, a sample structured response with invoice number, seller, buyer, total, and line items, and a vector-search query over stored invoices.
Git & GitHub Tutorial for Beginners (2026)
This step-by-step tutorial from Coder Coder is a beginner’s introduction to version control, covering the core local Git workflow — initializing a repository, staging and committing, reading file diffs, making changes after staging, and committing without staging — along with git log, branch, merge, and revert.
Command Line Basics for Beginners
freeCodeCamp published a beginner-friendly command line course that starts by demystifying the terminal and then moves into day-to-day shell basics: inspecting file trees with ls, navigating directories, creating and deleting files with touch and rm, creating and removing directories with mkdir, rmdir, and -r, and writing and reading files with echo and cat. The course also links to an interactive Scrimba version and frames the practice around building the file structure for a quiz game.
How the Model Context Protocol (MCP) actually works
This short explainer from Google Cloud Tech, presented by Smitha Kolan, covers MCP as a standard way for AI agents to discover and interact with external tools, data, and resources. It walks through the API/AI integration problem, what MCP connects to, client/server mechanics, core components such as tools, prompts, resources, and context, how MCP differs from a traditional API, and a practical assistant example.
DuckCon #7 (Amsterdam, June 2026)
DuckDB published the DuckCon #7 playlist from Amsterdam, with 12 talks on DuckDB and DuckLake use cases. The playlist covers Iceberg/Postgres integration, DuckDB for cancer genomics, ggsql, phage genomics workflows, search-first lakehouse retrieval for agents, SQLRooms for local-first analytics apps, DuckDB as a MariaDB storage engine, PySpark-to-DuckDB modernization, DuckLake on Hetzner, UK wind policy analysis, SQL over listening history for agentic access, and native app development with DuckDB.
Book of the Week
This week’s focus is on a machine learning book — The Orange Book of Machine Learning - Green edition by Carl McBride Ellis, PhD. The book focuses on supervised learning for tabular data, with an emphasis on making predictions through regression and classification. Instead of trying to cover every possible machine learning topic, it focuses on the workflow many data scientists use in practice: statistics, exploratory data analysis, data cleaning, validation, feature engineering, model selection, and modern tabular modeling. The Green edition is the actively maintained version, published on Leanpub, with 238 pages, 150 original figures, links to 30 Jupyter notebooks, and more than 950 hyperlinks to packages and academic references.
Topics Covered
Statistics and EDA — core statistical ideas, exploratory analysis, and the early checks that shape a tabular machine learning project.
Data cleaning — preparing messy tabular datasets before model training.
Cross-validation — evaluating models with validation strategies that reduce overfitting and leakage.
Interpolation and smoothing — handling continuous signals and noisy patterns in data.
Regression — building supervised models for continuous prediction tasks.
Classification — modeling categorical outcomes and comparing classification approaches.
GLM and GAM — using generalized linear and additive models as interpretable modeling tools.
Ensemble estimators — working with tree-based and boosted methods, including tools such as CatBoost, LightGBM, and XGBoost.
Hyperparameter optimization — tuning model behavior in a structured way.
Feature engineering and tabular foundation models — selecting useful predictors and introducing newer tabular foundation model approaches such as TabPFN and TabICL.
This book is ideal for data scientists, machine learning practitioners, and Python users who work with tabular data and want a practical reference for supervised regression and classification workflows.
The book is available for purchase on the publisher’s website and on Amazon. The companion GitHub page is available at Carl-McBride-Ellis/TOBoML.
Have any questions? Please comment below!
See you next Saturday!
Thanks,
Rami
Thanks for reading Rami’s Data Newsletter! Subscribe for free to receive new posts and support my work.
Disclaimer: I use AI to help edit the content in this newsletter. If you spot a mistake, please leave a comment — I’d appreciate the heads-up.