
Issue 65: The Durbyn Project, DeepSeek in Practice, New Tutorials
A weekly curated update on data science and engineering topics and resources.

This week's agenda:
Open Source of the Week - the Durbyn project
New learning resources - Harvard’s R course, Django tutorial, SQL course, Databricks end-to-end project
Book of the week - DeepSeek in Practice by Andy Peng, Alex Strick van Linschoten, and Duarte O.Carmo.
The newsletter is also available on LinkedIn and Medium.
Do you have a Medium subscription? Please read it on Medium!

Are you interested in learning how to set up automation using GitHub Actions? If so, please check out my course on LinkedIn Learning:
Open Source of the Week
It’s been a while since we had a Julia project here, and this week’s focus is on Durbyn - a Julia package for time series forecasting applications. This project by Resul Akay is inspired by R’s forecast package and provides implementations of core time-series statistical models.
Project repo: https://github.com/taf-society/Durbyn.jl
Key Features
Durbyn supports a wide variety of forecasting algorithms, including exponential smoothing (ETS/SES/Holt/Holt-Winters), auto- and manual ARIMA, ARAR/ARARMA, BATS/TBATS
Formula Interface - it provides a declarative interface for model specification with full support for tables, regressors (features in ML terminology), model comparison, and panel data.
Performance - the library leverages Julia’s high performance, and it is multi-threaded by default when fitting models across multiple time series
Here is an example for setting up an ARIMA model with regressors:
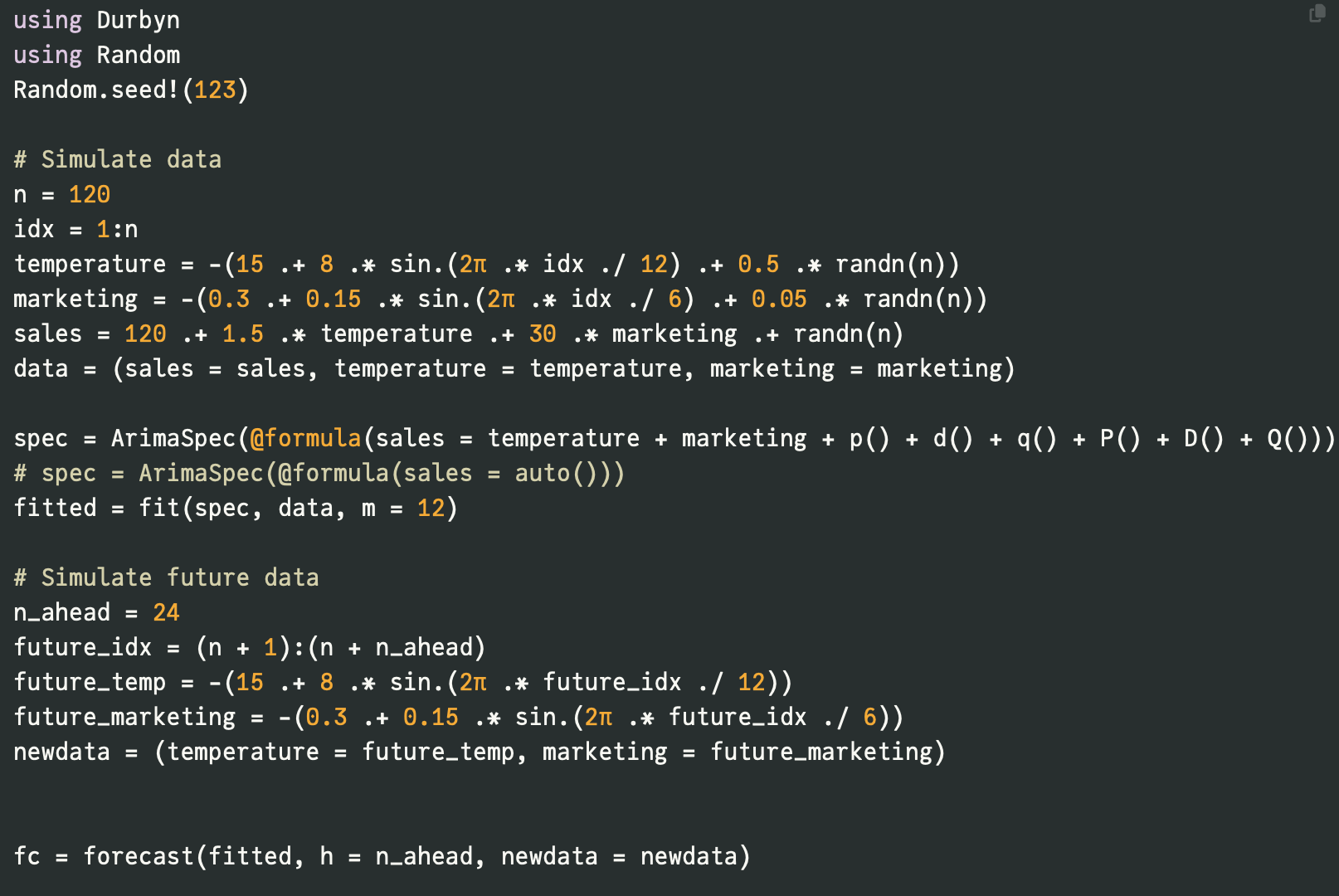
More details are available in the project documentation.
License: MIT
New Learning Resources
Here are some new learning resources that I came across this week.
Harvard R Programming Course
Harvard released a new CS course - Intro to R Programming, and it covers the following topics:
Introduction
Representing Data
Transforming Data
Applying Functions
Tidying Data
Visualizing Data
Testing Programs
Packaging Programs
AI Researcher Tutorial
The following tutorial by Vuk Rosić focuses on the mathematical foundations of AI, and it covers the following topics:
Math concepts - derivatives, vectors, gradients, etc
Probability
PyTorch and tensors
Matrix algebra
Activation functions
Neural network
Attention mechanism
GPT architecture overview
Django Tutorial
The following tutorial by NeuralNine is beginner-friendly to Django, a Python web framework.
SQL Full Course
The following course provides an in-depth introduction to SQL. This 10-hour course is beginner-level, and it starts from the basics of SQL comments all the way to advanced topics such as subqueries, CASE WHEN, stored procedures, loops, cursors, triggers, exception handling, etc.
Databricks End-To-End Project
Hands-on Databricks tutorial by Thomas Hass, focusing on building an end-to-end pipeline. This includes setting data and ML pipelines, a dashboard, and UI.
Book of the Week
This week’s focus is on a new book - DeepSeek in Practice by Andy P. , Alex Strick van Linschoten , and Duarte O.Carmo. The book provides a hands-on guide to working with the DeepSeek, an open-source LLM model.
The book covers the following topics:
Introduction to DeepSeek
Working with DeepSeek via API
Model fine-tuning
Running agents with DeepSeek
Using DeepSeek in production

The book is ideal for AI developers, engineers, and data scientists aiming to leverage open-source LLMs like DeepSeek for their projects. Prior knowledge in Python programming, APIs, and machine learning concepts is required.
The book is available online on the publisher’s website, and a hard copy can be purchased on Amazon.
Have any questions? Please comment below!
See you next Saturday!
Thanks,
Rami
Really appreciate how youcompiled these resources, especially the Durbyn project for Julia users doing time series work. The formula interface approach is interesting becuase it mirrors R's syntax but gets Julia's performance gains, which could make it easier for R users to transition without the usual friction. What I'm curious about is whether multi-threading by default might actually create overhead for smaller datasets where the coordination cost outweighs the paralell gains. Either way, solid curation as always.